

Summary
This article explores a sophisticated, data-driven approach to maximizing profits in European football betting, highlighting its relevance for both casual bettors and seasoned professionals seeking an edge. Key Points:
- Identify and exploit subtle inefficiencies in European football betting markets using high-frequency data and algorithms to capitalize on fleeting arbitrage opportunities.
- Develop a hybrid predictive model by integrating machine learning with Bayesian inference to enhance accuracy and quantify uncertainty in predictions.
- Incorporate qualitative factors such as team form, player morale, and weather conditions into quantitative models for improved betting outcomes.
First and foremost, we need to gather historical match data. A reliable source for this information is Football-Data.co.uk. Specifically, the page located at https://www.football-data.co.uk/downloadm.php provides extensive datasets covering European football championships in 11 different countries. Each file contains a complete season's worth of data for a particular league. The information is organized in Excel files that feature multiple sheets, with each sheet dedicated to the match data from various European championships within these nations.
Key Points Summary
- Compare betting odds for all football games across various leagues in Europe.
- Bwin offers a wide range of betting markets for international competitions like the UEFA European Championship and FIFA World Cup.
- Soccerbase.com provides comprehensive services including match odds, free betting tips, and results.
- Find the best accumulator odds from over 25 leading UK bookmakers.
- Predictions and tips available for major leagues such as La Liga, Serie A, Ligue 1, Bundesliga, and others.
- Stay updated with real-time Euro football odds to enhance your betting experience.
If you`re into football betting, there`s a wealth of options out there. From local leagues to international tournaments, you can find competitive odds that suit your needs. Whether you`re placing a simple bet or crafting an accumulator with multiple matches, staying informed about the latest odds and predictions can make all the difference. It`s exciting to engage with your favorite teams while potentially making some profits along the way!
Extended Comparison:| Source | Betting Markets | Competitions Covered | Additional Features | Real-time Odds |
|---|---|---|---|---|
| Bwin | Wide range of betting markets | UEFA European Championship, FIFA World Cup | Live betting options, cash-out feature | Yes |
| Soccerbase.com | Match odds, free betting tips | Major leagues including La Liga and Serie A | Comprehensive results database, expert analysis | Yes |
| Oddschecker.com | Accumulator odds comparison from multiple bookmakers | All major European leagues and competitions | Betting insights, tips from analysts | Yes |
| Betfair Exchange | Peer-to-peer betting markets | Premier League, Champions League | Back and lay bets options | Yes |
| William Hill | Extensive selection of markets including specials | International tournaments and domestic leagues | Enhanced odds offers, promotions for new users | Yes |
After downloading all the files into a single folder, the subsequent step is to combine them into a unified dataset. When preparing for an analysis of historical data, it's crucial to ensure that the datasets are formatted uniformly. This consistency facilitates seamless merging and analysis. The process entails standardizing column names, addressing any missing data, and verifying that all records have accurate timestamps. By meticulously cleaning and prepping the data from the outset, we can sidestep errors and inconsistencies that could undermine the integrity of our findings. Below is a Python script designed to achieve this:
import pandas as pd def merge_and_sort_files(file_paths, output_file): all_dataframes = [] for file_path in file_paths: all_sheets = pd.read_excel(file_path, sheet_name=None) if not all_dataframes: reference_columns = list(all_sheets[next(iter(all_sheets))].columns) for sheet in all_sheets.values(): missing_cols = [col for col in reference_columns if col not in sheet.columns] sheet = pd.concat([sheet, pd.DataFrame(columns=missing_cols)], axis=1) sheet = sheet[reference_columns] all_dataframes.append(sheet) combined_dataframe = pd.concat(all_dataframes, ignore_index=True) combined_dataframe["Date"] = pd.to_datetime(combined_dataframe["Date"], format='%d-%m-%Y', errors='coerce') combined_dataframe.sort_values(by=["Date", "Time", "Div"], inplace=True, ignore_index=True) combined_dataframe["Date"] = combined_dataframe["Date"].dt.strftime('%d-%m-%Y') combined_dataframe.to_csv(output_file, index=False) file_paths = [ "all-euro-data-2024-2025.xlsx", "all-euro-data-2023-2024.xlsx", "all-euro-data-2022-2023.xlsx", "all-euro-data-2021-2022.xlsx", "all-euro-data-2020-2021.xlsx", "all-euro-data-2019-2020.xlsx", "all-euro-data-2018-2019.xlsx", "all-euro-data-2017-2018.xlsx", "all-euro-data-2016-2017.xls", "all-euro-data-2015-2016.xls", "all-euro-data-2014-2015.xls", "all-euro-data-2013-2014.xls", "all-euro-data-2012-2013.xls", ] output_file = "final_combined_football_data_sorted.csv" merge_and_sort_files(file_paths, output_file)The final output, named final_combined_football_data_sorted.csv, features a comprehensive list of matches organized by date, time, and league division. For a detailed breakdown of the dataset's columns, please refer to the accompanying Notes.txt file available on our website. Following the creation of our historical dataset, we proceed to load it and incorporate additional columns that will provide deeper insights:
# Example usage output_file = pd.read_csv('final_combined_football_data_sorted.csv') # Add over/under column output_file['TG'] = output_file['FTHG'] + output_file['FTAG'] output_file.loc[:, 'OU'] = output_file['TG'].apply(lambda x: 'O' if x > 2.5 else 'U') # Add Both teams to score column output_file['GGNG'] = output_file['FTHG'] * output_file['FTAG'] output_file.loc[:, 'GG'] = output_file['GGNG'].apply(lambda x: 'G' if x > 0 else 'N') #keep only necessary columns output_file = output_file[['FTR','HTR', 'OU', 'GG', 'B365H', 'B365D', 'B365A', 'B365>2.5', 'B365<2.5']]Market Efficiency, Implied Probabilities, and Dynamic Odds Movements
To enhance the depth and accuracy of the discussion, we will focus on two key areas: implied probabilities in relation to market efficiency and the dynamic nature of odds movement through time-series analysis.To improve the reliability of our analysis, we incorporate odds that fall within a 1% margin of the designated values. This approach broadens our sample size by including matches that possess similar odds, even when exact matches are limited. Below are two Python functions designed to filter the data based on our chosen set of odds:
def forecast_match_HDA_odds(df, home_odds, draw_odds, away_odds): # Define the range for odds (plus/minus 1%) home_range = (home_odds * 0.99, home_odds * 1.01) draw_range = (draw_odds * 0.99, draw_odds * 1.01) away_range = (away_odds * 0.99, away_odds * 1.01) # Filter rows where the odds are within the given ranges filtered_df = df[ (df['B365H'] >= home_range[0]) & (df['B365H'] <= home_range[1]) & (df['B365D'] >= draw_range[0]) & (df['B365D'] <= draw_range[1]) & (df['B365A'] >= away_range[0]) & (df['B365A'] <= away_range[1]) ] return filtered_dfdef forecast_match_OU_odds(df, Ov_odds, Un_odds): # Define the range for odds (plus/minus 1%) Over_range = (Ov_odds * 0.99, Ov_odds * 1.01) Under_range = (Un_odds * 0.99, Un_odds * 1.01) # Filter rows where the odds are within the given ranges filtered_df = df[ (df['B365>2.5'] >= Over_range[0]) & (df['B365>2.5'] <= Over_range[1]) & (df['B365<2.5'] >= Under_range[0]) & (df['B365<2.5'] <= Under_range[1]) ] return filtered_dfThe next phase requires us to delve into past match results that share similar odds. By analyzing these filtered statistics, we can gain insights into the likelihood of different outcomes. The function below carries out this statistical analysis:
import numpy as np import pandas as pd from scipy import stats def calculate_statistics(df, cols): column_pairs = list(zip(*[df[col] for col in cols])) unique_values = list(set(column_pairs)) percentile_results = pd.DataFrame() index_diff_dict = {} for v in unique_values: index_diff_dict[v] = [index for index, value in enumerate(column_pairs) if value == v] for v in index_diff_dict.keys(): indices_diffs = [index_diff_dict[v][0]] + [index_diff_dict[v][i] - index_diff_dict[v][i - 1] for i in range(1, len(index_diff_dict[v]))] + [len(df) - index_diff_dict[v][-1]] stats_dict = { 'forecast': v, 'matches_count': len(indices_diffs) - 1, 'last_interval': indices_diffs[-1], 'median': int(np.percentile(indices_diffs, 50)), 'P75': int(np.percentile(indices_diffs, 75)), 'P90': int(np.percentile(indices_diffs, 90)), 'P95': int(np.percentile(indices_diffs, 95)), 'P99': int(np.percentile(indices_diffs, 99)), 'max': int(np.max(indices_diffs)), 'Pct_score': int(stats.percentileofscore(indices_diffs, indices_diffs[-1])) } percentile_results = pd.concat([ percentile_results, pd.DataFrame([stats_dict])], ignore_index=True) percentile_results.sort_values(by=['last_interval', 'Pct_score'], ascending=[False, False], inplace=True) percentile_results['Norm'] = round(100 * percentile_results['matches_count'] / percentile_results['matches_count'].sum(), 2) percentile_results['Prod'] = (percentile_results['Norm'] * percentile_results['Pct_score']).astype(float).round(2) percentile_results['Odds'] = round(percentile_results['matches_count'].sum() / percentile_results['matches_count'], 2) percentile_results = percentile_results.sort_values(by='Prod', ascending=False).reset_index(drop=True) return percentile_resultsSure! Please provide the text you would like me to rewrite, and I will assist you with that.
Our methodology deliberately omits direct references to the specific teams involved in a match. Instead, we operate under the premise that bookmakers like Bet365 have already taken into account all pertinent factors—such as team performance, player injuries, and historical encounters—in their odds calculations. By concentrating on these odds, we simplify our analysis and reduce any subjective bias, placing our trust in the numerical data as it provides a thorough and unbiased assessment of the match.
Let's consider a recent match listed on Bet365, which offers the following odds: Home victory at 1.85, a Draw at 3.30, and an Away win at 4.50. Here’s how to interpret these figures effectively:
home_odds = 1.85 draw_odds = 3.3 away_odds = 4.5 filtered_df = forecast_match_HDA_odds(output_file, home_odds, draw_odds, away_odds) if len(filtered_df) > 100: stat = calculate_statistics(filtered_df, ['FTR']) print(stat)To achieve dependable predictions, it is essential to gather a substantial amount of data. A benchmark of 100 historical matches has been established, striking a balance between ensuring statistical validity and the practical accessibility of data. By analyzing at least 100 matches, we can ensure that the sample size is adequate to yield significant insights while minimizing the chances of anomalies affecting the results. This methodology produces a table that ranks the likelihood of various outcomes. For instance, take a look at the following table:

In this scenario, a victory for the home team is determined to be the most probable outcome. Furthermore, the suggested odds correspond with those offered by Bet365, indicating it could represent a valuable betting opportunity. The aim here is to pinpoint predictions where the odds are equal to or exceed those available through Bet365. Additional methods for utilizing the code are outlined below:
home_odds =1.85 draw_odds = 3.3 away_odds = 4.5 filtered_df1 = forecast_match_HDA_odds( output_file, home_odds, draw_odds, away_odds) if len(filtered_df1)>100: print(len(filtered_df1)) stat = calculate_statistics(filtered_df1, ['FTR']) print(stat) stat = calculate_statistics(filtered_df1, ['GG']) print(stat) stat = calculate_statistics(filtered_df1, ['HTR']) print(stat) stat = calculate_statistics(filtered_df1, ['HTR','FTR']) print(stat) stat = calculate_statistics(filtered_df1, ['FTR','GG']) print(stat) Ov_odds, Un_odds = 2.05, 1.75 filtered_df =forecast_match_OU_odds(output_file, Ov_odds, Un_odds) if len(filtered_df)>100: stat = calculate_statistics(filtered_df, ['OU']) print(stat) stat = calculate_statistics(filtered_df, ['GG']) print(stat)The information presented above generates the following tables:




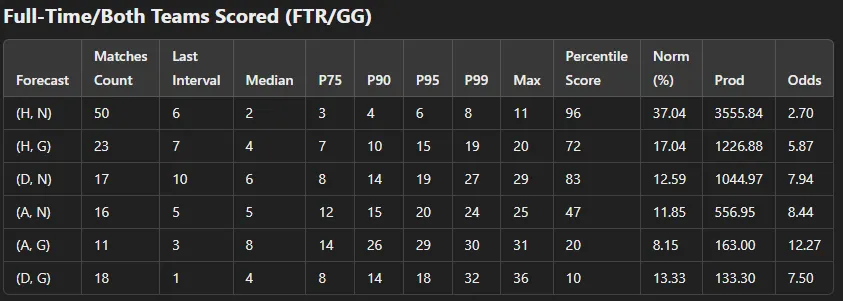


Advanced Statistical Modeling and Dynamic Odds Monitoring for Profitable Sports Betting
Incorporating advanced statistical modeling techniques can significantly enhance the identification of value bets in sports betting. Rather than relying solely on basic historical averages, sophisticated methods such as Poisson Regression and machine learning algorithms (like Gradient Boosting Machines and Neural Networks) should be employed to assess various factors influencing match outcomes, including team form, injuries, referee bias, weather conditions, and home advantage quantified through Elo ratings or Dixon-Coles models. These approaches not only provide more accurate probability predictions but also measure the uncertainty tied to those predictions. Calibration of these models is crucial for aligning predicted probabilities with observed frequencies across extensive datasets, ultimately leading to improved identification of value bets and a deeper understanding of risk-reward dynamics.Furthermore, dynamic odds monitoring across multiple bookmakers is essential for maximizing profitability. By utilizing automated systems that track real-time odds fluctuations from various platforms, players can capitalize on arbitrage opportunities where combined probabilities exceed 100%, as well as detect discrepancies between model predictions and available odds. This necessitates robust software equipped with high-frequency data acquisition capabilities and sophisticated algorithms for simultaneous value bet identification across numerous sources. Additionally, integrating algorithmic trading elements—such as order book analysis for liquidity assessment and strategic order placement—can further optimize betting strategies. To capture qualitative market influences often overlooked by traditional statistical methods, sentiment analysis from social media or news sources can be invaluable. The ultimate aim is to create a dynamic system that swiftly identifies and seizes fleeting value opportunities in the betting landscape.
Finally, I welcome any thoughts or suggestions you may have to improve this piece. If you found this article helpful and are eager to explore more insights like these, I invite you to follow me on Medium. For those who haven’t yet joined the Medium community, starting is easier than ever—just click this link to begin your journey.
References
Football - Europe Betting Odds
Compare Football Europe Betting Odds, on all games played in all leagues. Stay updated with Odds Portal.
Source: Odds PortalFootball Betting Odds - Football Competitions
Betting on International Competitions From the UEFA European Championship to the FIFA World Cup, Bwin offers a wide range of betting markets for international ...
Source: Bwin Sports BettingEuropean Football Fixtures & Betting Odds - Matches
Euro football match coupon. Soccerbase.com offers the most comprehensive football betting service including match odds, free betting tips and results.
Source: Soccer BaseFootball Odds & Football Betting | Compare Accas at ...
Find the best odds for your accumulators. Compare accumulator odds across 25+ leading UK bookmakers. View all matches.
Source: OddscheckerEuropean Football Betting Tips & Bet Builder Predictions
We provide predictions and tips for La Liga, Serie A, Ligue 1 and the Bundesliga, as well as the Swedish Allsvenskan and Norwegian Eliteserien.
Source: Andy's Bet ClubOther European Leagues - Football
Turkish Super Lig Betting: Exciting title battle on in one of the last remaining leagues. Daily Acca The Daily Acca: Goals to flow in Belgian top flight.
Source: BetfairEuro Betting Odds: Best football Odds 7/7 (Europe)
Find the best Euro odds (Europe) for your football bets in Real Time with our odds comparison service.
Source: SportyTraderFootball Betting & Latest Football Odds - bet365
Want to place bets on your favourite teams? Check out the latest odds on our huge range of leagues and markets. View Latest Football Odds.
Source: Bet365
 ALL
ALL sports
sports
Discussions