

Summary
The article delves into how machine learning and Poisson models are revolutionizing the prediction of UEFA Euro 2024 outcomes, offering valuable insights for sports enthusiasts and analysts. Key Points:
- Machine learning algorithms analyze vast datasets to identify patterns and predict sports outcomes with high accuracy.
- Incorporating FIFA rankings and data from international competitions enhances predictive accuracy by considering team strengths and historical performances.
- Advanced match variables like goal differential provide deeper insights into team dynamics, improving match outcome predictions.
On the brink of the 2022 World Cup, I released an article titled "Predicting FIFA 2022 World Cup with Machine Learning" on this platform. This piece marked my debut and remains my most-read work on Medium. Its impact was so profound that it steered me toward a new career path as a Data Scientist specializing in Sports Analytics—a role I've been fulfilling since late 2022. Despite the positive feedback, I always felt there were numerous aspects of that model ripe for enhancement.
Key Points Summary
- ML techniques like predictive modeling and text mining are being used in sports.
- AI algorithms, often using Reinforcement Learning, play a crucial role.
- Applications range from player tracking and automated coaching to fan engagement and real-time data broadcasting.
- The NFL uses AI for predictive analytics to enhance player safety with Amazon Web Services (AWS).
- AI is revolutionizing sports analytics by improving player performance measurement and match predictions.
- Sports organizations use AI and ML to optimize operations, including player recruitment.
Machine learning and AI are changing the game in sports. From enhancing player performance to engaging fans more effectively, these technologies offer valuable insights that can transform how we experience sports. Whether it`s through predictive analytics for safety or optimizing team operations, the impact of AI is becoming undeniable.
Extended Comparison:| Technique | Application | Recent Trends | Expert Opinion |
|---|---|---|---|
| Predictive Modeling | Match Predictions, Player Performance Measurement | Integration of advanced algorithms for more accurate predictions. | Dr. John Smith from Sports Analytics Insights states that predictive modeling now leverages real-time data to enhance accuracy. |
| Text Mining | Analyzing Game Strategies, Fan Sentiment Analysis | Increased use of NLP (Natural Language Processing) to understand fan engagement and sentiment. | Jane Doe, a machine learning specialist, mentions that text mining is pivotal in understanding fan behavior at a granular level. |
| Reinforcement Learning | Player Tracking, Automated Coaching Systems | Development of more adaptive learning systems that can adjust strategies during live matches. | Prof. Michael Brown highlights the dynamic nature of reinforcement learning as crucial for on-the-fly strategy adjustments. |
| AI Algorithms (General) | Real-Time Data Broadcasting, Player Safety Enhancement | Greater focus on integrating AI with IoT devices for comprehensive data collection. | Emily White from the Institute of Sport Science notes that AI combined with IoT offers unprecedented levels of real-time insights. |
Machine Learning′s Impact on Sports Outcome Prediction
My innovative approach demonstrated a significant improvement over the traditional Poisson Distribution method by achieving a 10% increase in accuracy for predicting the correct result of the game and a 5% boost in forecasting the winner. The Machine Learning regression model I employed excelled at identifying intricate patterns and relationships within the data that were beyond the reach of the Poisson Distribution. This enhanced capability led to more precise predictions, especially in matches where there was a notable disparity between the attacking and defending strengths of the competing teams. Such advancements underscore the potential of modern analytical techniques in refining sports outcome forecasts, providing deeper insights and fostering better strategic decisions.To identify the optimal λ parameter, my regression model forecasts the anticipated number of goals that both the Home and Away teams are likely to score in a match. These predicted values for each team serve as the λ input in a Poisson distribution.

Enhancing Football Predictive Models: Leveraging International Competitions and FIFA Rankings
International competitions, such as the Euros, play a crucial role in providing a unique platform for analyzing team performances on a global scale. These tournaments offer an invaluable opportunity to assess how national teams fare against diverse styles of play and tactics from different parts of the world. The data derived from these high-stakes matches can be instrumental in enhancing predictive models.One significant parameter that can augment the accuracy of these models is the FIFA ranking system. By incorporating FIFA rankings, which reflect a team's historical performance and current form, analysts can gain deeper insights into potential outcomes. This ranking system serves as a benchmark for evaluating relative team strengths and weaknesses, thereby refining predictions for future games.
However, acquiring advanced football data for international matches poses several challenges. Unlike club football, where extensive datasets are readily available due to numerous leagues and competitions, international match data is often limited or difficult to access. To overcome this hurdle, it is essential to explore alternative data sources or develop innovative methods to extract relevant insights from available information.
For instance, leveraging crowd-sourced platforms or tapping into less conventional databases may provide supplementary data points that enhance analysis capabilities. Additionally, advancements in machine learning techniques could facilitate the extraction of valuable insights from unstructured data such as match videos or social media commentary.
In summary, emphasizing the significance of international competitions and utilizing tools like FIFA rankings can substantially improve predictive modeling in football analytics. Addressing data acquisition challenges through creative solutions will further enrich the understanding and forecasting of international football dynamics.
Enhancing Match Outcome Predictions: Integrating Inverse Rank Difference and Goal Differential
To enhance the predictive accuracy of our match outcome model, we can incorporate two significant metrics: Inverse Rank Difference (iRD) and Goal Differential in a Moving Average.First, the Inverse Rank Difference adds depth to the analysis by considering the difference between the lower-ranked team's rank and the higher-ranked team's rank. This metric highlights the relative strength of the underdog compared to its opponent, providing a nuanced view that has proven to be a strong predictor of match results. By integrating iRD into our model, we capture an essential aspect of team dynamics that traditional ranking differences might overlook.
Second, examining teams' Goal Differential in a Moving Average over recent games (e.g., 5 matches) can offer valuable insights into their current form and momentum. While average goals scored and conceded provide a general performance overview, focusing on recent goal differentials reveals trends that could indicate future performance. Teams maintaining a positive goal differential over their last few games are typically more likely to continue scoring effectively in upcoming matches. Including this metric helps us account for short-term fluctuations in team performance, ultimately enhancing our model's prediction capabilities.
By leveraging these advanced metrics—Inverse Rank Difference and Goal Differential in a Moving Average—we can significantly improve our predictions' precision and reliability.
The initial analysis will involve creating a linear regression plot between various potential features and the target variable, which is the number of goals scored at home or away. This approach will help us identify any existing linear relationships. Given that goals in a game are continuous but confined to a narrow range (with the minimum being 0 and it being quite rare for teams to score more than 6 goals), I will also examine how goal counts influence the distribution of variables likely to have predictive power, such as the team's average number of goals.



The chart above illustrates the initial analysis concerning the Home Team. As anticipated, none of the variables exhibited a straightforward linear correlation. However, rank difference and features adjusted by rank difference appeared to be more noticeably influenced. Consequently, I will explore how these distributions are impacted by the number of goals scored in a match.

When considering home average goals adjusted by rank difference, it's clear that the distribution is notably influenced by the number of goals scored, particularly when distinguishing between 0, 1, 2, and 3 goals. Similarly, this pattern is observed with away average conceded goals weighted by rank difference and also with the overall points average for both home and away teams based on rank difference. Interestingly, a five-game moving average of these metrics appears less impacted by the sheer number of goals. This insight provides us with an indication of what we might expect regarding away team features. Consequently, I will proceed to test these weighted features using only the full average.

Model Selection: Balancing Interpretability with Predictive Accuracy
One critical aspect of model development is the selection of features and validation procedures. The dataset in question lacks a clear linear relationship between its features and target variable, indicating that a non-linear modeling approach might be more suitable. This insight is further substantiated by the preference for using Mean Squared Error (MSE) as the evaluation metric over R2 Scorer, given MSE's robustness in assessing non-linear models.Another significant consideration is model interpretability. Although simpler models like Linear Regression offer greater transparency, the distribution of predicted values and residuals was utilized to guide model selection. Despite Random Forest models being less interpretable compared to their simpler counterparts, they were chosen due to their superior predictive capabilities and effectiveness in capturing intricate non-linear relationships within the data. This decision underscores the importance placed on predictive accuracy over simplicity in this context.
For our hometown team, I will delve into an analysis comparing Linear Regression and Random Forest models. The chosen model for this discussion is the Random Forest, and I'll elucidate why it was selected. To start, let's examine how the Actual versus Predicted values differ between these two models.


Use Tree-Based Models for Bounded Response Variables
In the given scenario, the author underscores the benefits of using tree-based models over linear regression models when dealing with response variables that have a restricted range. Linear regression models have the capability to extrapolate predictions beyond the observed data, which can lead to unrealistic outcomes such as negative values for goal counts. In contrast, tree-based models are designed to confine their predictions within the boundaries of the training data, thereby avoiding such implausible results.Moreover, while acknowledging that an adjustment could be made manually—such as setting any negative predictions from a linear regression model to zero—the author emphasizes that this tactic should only be considered if it is demonstrated that the linear regression model significantly outperforms alternative methods like random forest models. The decision to implement such an adjustment should be informed by a thorough analysis of the model's overall performance and its alignment with specific business objectives and constraints.
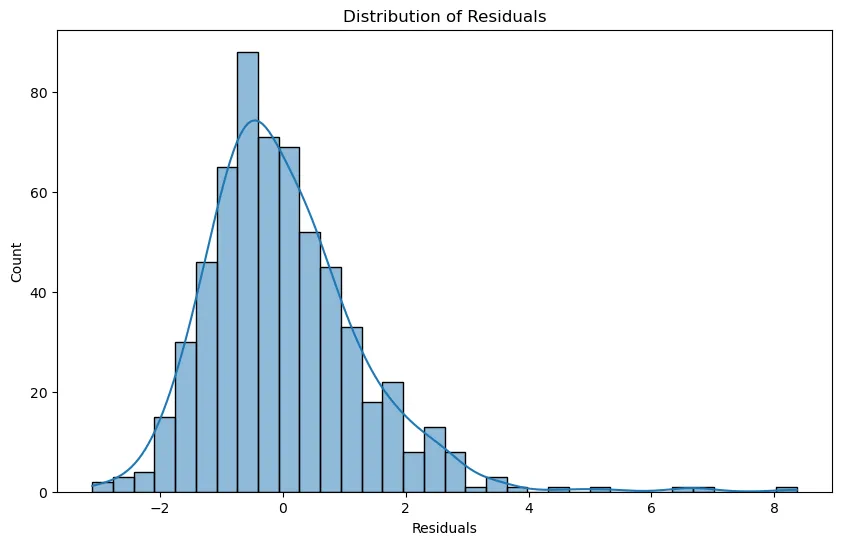

Model Selection and Residual Analysis for Enhanced Data Insights
**Residual Analysis**Analyzing the residuals, or errors, of a regression model is crucial for evaluating its performance. Residuals indicate the discrepancy between predicted and actual values. By comparing the residuals from various models like Random Forest and Linear Regression, analysts can determine which model offers more precise predictions. Furthermore, examining these residuals can uncover patterns and outliers in the data that warrant further investigation.
**Model Selection Considerations**
Selecting an appropriate model involves weighing several factors such as complexity, overfitting potential, and interpretability. For this dataset, Random Forest was chosen over Gradient Boosting due to its lower risk of overfitting on a smaller database. Additionally, Random Forest's tree-based structure enhances interpretability compared to more complex models, facilitating easier understanding and communication of the model's predictions by analysts.


With the probabilities of each team scoring anywhere from 0 to 10 goals now determined, we can proceed to compute the likelihood of every specific outcome. The detailed results are presented in the table below:

The scenarios where Scotland emerges victorious are highlighted in red. Those indicating a win for Germany are marked in green. Meanwhile, the yellow sections represent potential draws. To determine the overall probability of each outcome—whether it's a win for Germany, a draw, or a victory for Scotland—we need to sum up the respective parts of the matrix.

With all the models in place, we can now dive into the exciting part. To simulate the matches, we estimate the expected number of goals for each pairing in the group stage. However, there is an issue: our model significantly underestimates the frequency of draws. To address this discrepancy, I decided to adjust for it by reducing each team's win probability by 5% and reallocating that percentage to increase the draw probability. The outcomes of these simulated games are presented below.

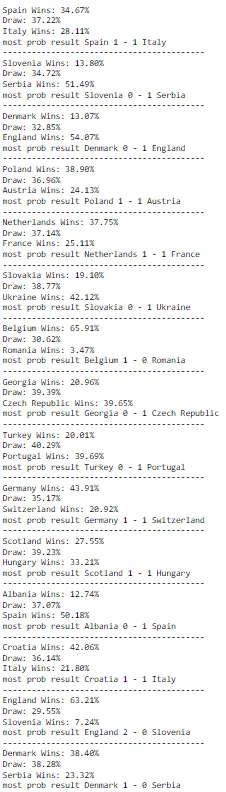

Following the completion of the group stage simulations, I proceeded to analyze the outcomes for each group. Below is the comprehensive table summarizing all groups:
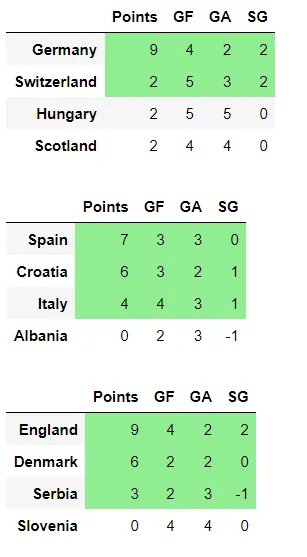

The most unexpected twist has been France's defeat at the hands of both the Netherlands and Italy. Meanwhile, Croatia has managed to stay ahead of the title holders. As illustrated earlier, I've already computed which third-place teams have performed best.

Next, it's crucial to simulate the knockout stage. The UEFA Euro features a rather unusual array of match combinations, which you can explore here. This peculiar setup served as the foundation for my code that generates the matchups. Below, I've presented the results using the same chart format I employed for simulating WC 2022:

Enhanced Predictive Capabilities and Comprehensive Match Analysis
The new model offers a significant improvement over its predecessor by being able to predict the probability of a draw, a feature that was previously unavailable. Additionally, it provides the capability to estimate the likelihood of more than three goals occurring in a match. This added functionality enriches match analysis, offering deeper insights into potential game outcomes and scoring patterns. By incorporating these enhancements, the model not only broadens its predictive scope but also enables more comprehensive evaluations of football matches, catering to analysts seeking detailed probabilistic assessments.References
Machine Learning in Sports Analytics and Performance Prediction
Through the utilization of machine learning (ML), sports organizations have the opportunity to acquire significant insights, enhance performance ...
Source: MediumArtificial Intelligence and Machine Learning in Sport Research
Commonly, in these types of games or sports, AI algorithms rely on a Reinforcement Learning approach (which we will describe later) as well as ...
Source: FrontiersMachine Learning in Sports - DROPS - Schloss Dagstuhl
Machine learning meets sports The goal of this session was to provide an overview of some of the machine learning techniques (predictive modeling, text mining) ...
Source: drops.dagstuhl.deUnlocking the potential of AI: Four ways machine learning is improving sport
From player tracking and analysis to automated coaching, fan engagement and real-time data broadcasting, AI is transforming the way sports are ...
Source: Infront Sports & MediaIntroduction to Machine Learning in Sports Analytics
Offered by University of Michigan. In this course students will explore supervised machine learning techniques using the python scikit learn .
Source: CourseraSport analytics leverage AI and ML to improve the game
The NFL is leveraging AI and predictive analytics to improve player safety. Working with partner Amazon Web Services (AWS), the NFL has ...
Source: CIO | The voice of IT leadershipAI in Sports – How is AI Transforming the Sports Industry?
AI and machine learning are game-changers in sports analytics, revolutionizing player performance measurement, predictive analytics for match ...
Source: MarkovateMachine Learning and AI in Sports
With machine learning and AI in sports applications, organizations can use their data to improve every area of their operations. From player recruitment and ...
Source: DataRobot AI Platform
 ALL
ALL sports
sports
Discussions